
EN PORTADA
Algunas experiencias del desarrollo de Big Data en Salud en Colombia
- ACHC
- Junio 13 de 2022
- 1:00 PM
En Colombia, diversos agentes del sistema de salud desde hace algunos años han empezado a implementar herramientas y proyectos soportados en Big Data. Desde el Gobierno nacional y los entes territoriales, se reconoce que la pandemia también aceleró el desarrollo de estos proyectos y presionó el análisis de datos para la toma de decisiones. Hospitalaria consultó a diversos agentes, quienes compartieron el estado actual de estos desarrollos e indicaron hacia dónde se orienta en el país la Big data en materia de salud.
Minsalud maneja 43.000 millones de registros de información en Sispro
Con una bodega de datos que integra 54 fuentes con alrededor de 43.000 millones de registros, un volumen de Big Data, el Sistema Integrado de Información de la Protección Social (Sispro) del Ministerio de Salud se constituye en una fuente invaluable de información que debe aprovecharse para contribuir a la transformación del sector salud.
Así lo afirmó Constanza Engativá Rodríguez, jefe de la Oficina de Tecnologías de la Información y la Comunicación (OTIC) del Ministerio de Salud y Protección Social, quien señala que las consultas de la información dispuesta en esta bodega de datos pasaron de 1,4 millones de consultas promedio en 2018, a 2,5 millones en 2020 y 2,8 millones en 2021: “Por la modalidad de autoconsulta, en 2021 se hicieron más de 2,8 millones de descargas de los cubos de datos dispuestos en Sispro”.
Aclaró que si bien en el Ministerio de Salud no se adelantan iniciativas de Big Data como tal, sí se trabaja en la explotación de esos datos a partir de las fuentes del sector integradas en las bodegas: “En el Ministerio no solamente recibimos información de las EPS, las IPS, los territorios, sino que integramos fuentes externas muy importantes como por ejemplo la Registraduría Nacional del Estado Civil y Migración Colombia, bases de datos que son reportadas al Ministerio y configuran un uso secundario de información para la toma de decisiones”.
La jefe de la OTIC reitera que, desde el concepto per se de la Big Data, no se trata solamente de tener muchos conjuntos de datos, sino saber qué hacer con esos datos, cómo aprovecharlos: “Aquí en los 2,8 millones de descargas de esos repositorios de información, muchos están haciendo un uso efectivo y productivo de esos datos para garantizar que el sistema de salud sea mucho mejor y, sobre todo, para que cada actor, EPS, IPS, tome mejores decisiones, haga planeación, cree programas de prevención, hagan control de riesgo, haga verificaciones en salud pública e incluso pueda visionar el tema de aseguramiento”.
Desde el Ministerio se trabaja en procesos en consolidación, organización y calidad del dato en el sistema de información que, dado su volumen, potencialmente podrían usarse en proyectos específicos de Big Data. Para ello, se utiliza la plataforma tecnológica propia y se exploran nuevas alternativas de tecnologías emergentes que respondan a las necesidades de información.
Cuando llega la pandemia por COVID-19, se potenciaron los sistemas de información y se crearon otros como Mi Vacuna; también potenciaron varias herramientas y afinaron otras. Por ejemplo, se avanza en el afinamiento del PAIWEB, tal y como lo informó Engativá Rodríguez: “[Se trata de] un sistema de información que tiene más de siete años, con una arquitectura establecida; estamos en proceso de afinamiento procurando garantizar que los usuarios puedan registrar la información de vacunación de COVID-19. Hemos adelantado iniciativas no solamente de afinar y optimizar el sistema, sino de facilitar herramientas a las IPS para que puedan subir de manera masiva la información”.
Asimismo, la funcionaria agregó que en la Oficina de Planeación se tiene la Unidad de Analítica, desde la cual se trabajan proyectos demostrativos: “En dos proyectos de analítica de data con algoritmos y modelos predictivos se busca generar política pública y tener reportes importantes en dos aspectos muy críticos para el país: cáncer de seno y multimorbilidad; la meta para este año es desarrollar siete proyectos demostrativos, incluyendo los mencionados, y otros sobre red de prestación de servicios, Plan Decenal de Salud Pública, indicadores y otros temas. De los 43.000 millones de registros que tenemos en la bodega de datos, están analizando más de 9.000 millones de registros para garantizar estos datos de analítica”.
Engativá Rodríguez también informó que en los Registros Individuales de Prestación de Servicios (RIPS) están desarrollando una herramienta que permita cruzar la Data de facturación electrónica con los RIPS, con el fin de cotejar lo que facturan las IPS versus lo que reportan en atenciones de salud. También sostiene que en la aplicación Minsalud Digital se tienen conectadas más de diez bases de datos que permiten garantizar la construcción de las Rutas Integrales de Atención en Salud (RIAS): “Tenemos ya dos Rutas Integrales, una de Promoción y Mantenimiento de la Salud y la Materno Perinatal, y vienen tres rutas más”.
La jefe de la OTIC de Minsalud considera que hay una gran tarea por terminar, porque la Data es un campo que no ha sido suficientemente explorado: “Estamos trabajando en un proyecto de resolución para garantizar el uso secundario de los datos, con el propósito de que las IPS, las EPS y los territorios tengan acceso a una Data analizada y protegida, que les permita generar procesos de analítica; que garantice la formulación de política pública; que les permita hacer control y gestión de riesgo; que les permita formular programas de promoción y prevención. Pero, sobre todo, que les permita verificar hasta dónde se puede predecir la salud de un paciente, dependiendo de lo que estamos analizando en esa Data”.
Y señaló que estos procesos son una tarea de todos, por lo que invitó a que cada actor del sector salud participe en ellos desde el rol que ocupe, para identificar que entra un nuevo actor importante en el ecosistema de la salud: “Ya no solamente los aseguradores, las farmacéuticas, los prestadores, el Estado, sino también la industria de tecnología, tienen grandes aportes que hacer a la salud”.
También agregó, “Todos los demás actores debemos dejar de ver al sector de tecnología como cliente y ellos deben dejar de vernos como proveedor, para que sea parte activa de la formulación de la generación de soluciones que la salud tanto necesita. Ver cómo integramos esas soluciones de hardware, de software, de conectividad, donde quiera que cada actor esté, para garantizar la analítica de datos y que cada día cada uno de nosotros desde nuestro rol podamos mejorar nuestro trabajo, porque cuando cualquier actor va a tomar una decisión, si la toma de manera informada, esa decisión será más acertada”.
Por último, Engativá Rodríguez señaló que le corresponderá al próximo Gobierno darles continuidad a los proyectos en temas de analítica, interoperabilidad de historia clínica y sistemas de información, “porque estos son proyectos de Estado que se necesitan y no dependen de un periodo de Gobierno, y la salud no va a evolucionar si no se hace un proceso adecuado y productivo de los datos”.
Nota: El Sispro está conformado por bases de datos y sistemas de información del sector sobre oferta y demanda de servicios de salud, calidad de los servicios, aseguramiento, financiamiento, promoción social. Suministra información estandarizada para la toma de decisiones del sector Salud y Protección Social.
Sivigila del INS pasó de manejar 2 a 20 millones de datos en un año con Big Data
El Sistema Nacional de Vigilancia en Salud Pública (Sivigila) del Instituto Nacional de Salud (INS), que en sus 15 años de existencia manejaba una Data de dos millones de registros en un año para 106 eventos de interés en salud pública que vigila en Colombia, con la llegada de COVID-19 pasó a manejar una Data cercana a 20 millones de registros en un año.
Así lo informó Claudia Marcella Huguett Aragón, coordinadora de Gestión de la vigilancia en salud pública del INS, quién explicó que “la llegada del COVID-19 cambió muchos paradigmas respecto a la cantidad de transacciones que pudiera tener incluso en un solo día, fue un evento cuya magnitud desbordó lo que trabajábamos habitualmente”.
Huguett explicó que esos 20 millones de registros se refieren solo a la Data estructurada de la notificación de casos de COVID, pero que existen muchos datos de otras fuentes cuya integración al proceso fue necesaria:
“En el día a día fue necesario adaptar una serie de metodologías, implementar varias estrategias, para que Colombia como ningún otro país en la región —incluso en el mundo fueron muy pocos— tuviera datos abiertos todos los días de manera nominal. Fue un incremento exponencial y no solamente en el número de registros que procesamos propios de la vigilancia, sino de otras fuentes que tuvimos que integrar al proceso para tener la información día a día”
En la Dirección de Vigilancia y Análisis de Riesgo, el equipo de ingenieros tiene trayectoria y experiencia en el sistema de información y en las adaptaciones del Sivigila, tal como lo explicó la directiva: “El proceso inició en 2020. Desde marzo hasta noviembre, manejamos una Data con herramientas comunes para todos los epidemiólogos, porque en el INS el procesamiento de los datos lo hacen los epidemiólogos, más que los ingenieros; ellos tienen formación en algunos gestores de bases de datos como el SQL que se maneja en el Instituto. Desde octubre iniciaron un proyecto con el gestor de bases de datos SQL, herramienta de fácil manejo; se hicieron muchas reuniones para entender el proceso y lograr generar el reporte diario de COVID-19 que presentaba el presidente Iván Duque en el programa de televisión Prevención y Acción durante la Pandemia”.
Huguett Aragón explicó cómo integraron datos de varias fuentes: “Como en todo proceso de análisis y desarrollo, primero fue necesario identificar los requerimientos; teníamos la fuente del Sivigila, pero teníamos que integrar la Red Nacional de Laboratorios a través de SisMuestras COVID-19, el repositorio al cual llegan todos los resultados de PCR o pruebas de antígenos, una data de millones de registros. Teníamos que integrar información de SegCovid19, plataforma que creó el Ministerio de Salud para seguimiento a los pacientes, porque diariamente generábamos la información de si estaba en Hospitalización General, en Unidad de Cuidados Intensivos (UCI) o si ya le habían dado egreso; teníamos que integrar la fuente del Ministerio del Interior para determinar cuáles eran indígenas y tenemos hoy integración de las fuentes de gestantes del país. Y para incluir los datos de fallecidos por COVID-19, cuya fuente oficial son los certificados de defunción, fue necesario integrar diariamente la información del RUAF (Registro Único de Afiliados)”.
Además, durante la pandemia lograron un objetivo perseguido durante años: la integración mediante servicios web o Web Service de la validación del documento de un paciente afiliado al sistema de salud, a través de la ADRES. Así lo indicó la directiva: “Logramos hacer esa integración con apoyo del Ministerio de Tecnologías de la Información y las Comunicaciones (MinTIC); es decir que hoy en día en el Sistema General de Seguridad Social en Salud introduces la información del documento de un paciente y te dice los nombres, apellidos, fecha de nacimiento, edad, tipo de aseguramiento, asegurador”.
Huguett Aragón presentó cifras alcanzadas en el proceso con Big Data: “Solo en el Sistema de Vigilancia (Sivigila) pasamos de 2 millones a casi 20 millones de registros en un año; en SisMuestras alcanzamos desde 2020 hasta julio de 2021 cerca de 14 millones de registros, hoy deben ser muchos más. Desde 2020 y hasta julio de 2021, tuvimos un procesamiento cercano a 14.000 o 15.000 registros de SisMuestras diarios; en SegCovid19, la plataforma de seguimiento a pacientes, teníamos un promedio de casi 3.000 ingresos diarios. Esa información se procesaba y registrábamos 67.000 egresos diarios, o sea, podíamos saber cuántos ingresaban a hospitalización y cuáles egresaban. En RUAF, el registro con certificados de defunción, procesábamos el año pasado 230.000 registros todos los días, porque teníamos que cruzar bases de datos de positivos de COVID con el histórico del RUAF, para saber cuándo cargaban un certificado de defunción de un paciente positivo”.
Para procesar esa información que confluía de muchas entidades, el grupo técnico de la Dirección de Vigilancia del INS organizaba mesas de trabajo con sesiones hasta de 20 horas diarias para generar el reporte. Se hizo trabajo intersectorial con otras dependencias y algunos Ministerios, para unificar información de distintas fuentes; y en la Dirección de Vigilancia del INS organizaron grupos de trabajo. Con la utilización de Big Data y Analítica de Datos, se agilizó enormemente y se robusteció el sistema de vigilancia.
Avances del proyecto Sivigila 4.0
La directiva del INS indicó que “Este año celebraremos 15 años del Sistema de Información del Sivigila, que se ha adaptado a las necesidades del país y a los cambios tecnológicos, pese a las limitaciones. Considerando que en los niveles locales hay municipios categoría 3, 4, 5 que no pueden hacer procesos de tecnología e información. En 2018 hicimos una transformación en la arquitectura y la estructura tecnológica del sistema de información. Creamos un proyecto denominado Sivigila 4.0 de varias fases; la primera de ellas fue el cambio de la estructura. Dentro de la arquitectura se hizo un sistema integrado que contemplara tipos de escenarios como una notificación tradicional en una aplicación de escritorio, un módulo de aplicación web, la posibilidad de hacer interoperabilidad a través de diversas formas (una de ellas, servicios web), y componentes que no teníamos”.
En este proyecto a mediano y largo plazo, ya desarrollaron varias fases y componentes, como la implementación de un módulo de captura de datos en línea y la construcción de un módulo para detección de alertas. El INS maneja Gestión del Riesgo detectando alertas en todo el país por medio de Data estructurada o Data no estructurada (redes sociales, rumores, medios de comunicación), a partir de esta Data, se generan señales que deben verificarse para determinar si deben hacerse intervenciones. El módulo ya está construido y opera en una herramienta, pero será integrado a todo el proyecto Sivigila 4.0. Asimismo, Huguett afirmó “También se viene automatizando un módulo de expertos que incorpora lógicas de algoritmos utilizadas por los epidemiólogos para depuraciones de bases de datos, y así fortalecer la proyección de los datos a nivel nacional; este módulo sirve a niveles locales de municipios y distritos que no pueden procesarlos, para observar cambios en muchas variables que captamos en el Sistema de Vigilancia. Y se crearon unos dashboard (tablero o cuadro de mandos) por eventos. Tenemos información desde 2007 hasta 2021, con detalle de IPS, EPS, desagregación por sexo, por municipio, una cantidad de información que se genera para uso del Instituto y de todos los niveles del sistema”.
Factor de éxito en Big Data: el talento humano
“El factor de éxito en un proyecto de Big Data es la calidad del talento humano que hay detrás; es tener un equipo que, como dicen en Sistemas, “comprenda el negocio”, los mecanismos, los algoritmos implícitos; que al hacer el procesamiento de una Data conozca muy bien la fuente y sepa qué se necesita. Yo no soy ingeniera de sistemas. Tengo formación en sistemas de información, pero de base soy profesional de la salud, y el engranaje que logramos entre los epidemiólogos con los equipos de ingenieros y gerentes de sistemas de información fue fundamental para que ellos ‘entendieran el negocio’, que lograran traducir la necesidad que teníamos. La gente ve los reportes de COVID-19, pero el proceso que hay detrás demanda días enteros de trabajo y gran calidad del talento humano, porque existen herramientas en ERP, en Phyton, en SQL. Pero si no hay alguien que conozca cómo estructurar este tipo de proyectos y cómo hacer su procesamiento, no sería fácil; no es viable”.
Así distinguió Huguett la importancia del trabajo del talento humano del INS con la generación del reporte COVID-19. Y agregó: “El INS mantuvo un compromiso tan grande para generar el reporte COVID que, en tiempo de Pandemia, no hubo un solo día que trabajáramos en casa, teníamos que desplazarnos todos los días, de lunes a domingo, continuábamos conectados en las noches, porque teníamos muchas tareas: resolver problemas, escuchar las necesidades de entidades territoriales, escuchar a Presidencia de la República sobre lo que querían en el reporte que presentaba el presidente Duque”.
Mientras los médicos luchaban contra la COVID-19 en los hospitales, el talento humano del INS cumplía otro rol como personal de salud en la búsqueda de información de la Pandemia: “Nosotros estábamos en la primera línea también, pero en este caso la primera línea de atención que no figura son los analistas de datos, personas que hacen turnos igual que en un hospital, a veces de 24 horas, toda la semana de lunes a domingos, haciendo todo el procesamiento de millones de registros”.
En el procesamiento de datos y generación del reporte de COVID-19 en el INS participan unas 110 personas, 30 de ellas con disponibilidad de lunes a domingo. Y en las Secretarías Departamentales de Salud, equipos de 10 a 30 personas trabajan en función de generar y analizar datos, o sea que miles de personas trabajan en Big Data sobre temas de COVID-19 en el país.
Observatorio de Salud de Bogotá - SaluData: más de 750 días de información de COVID
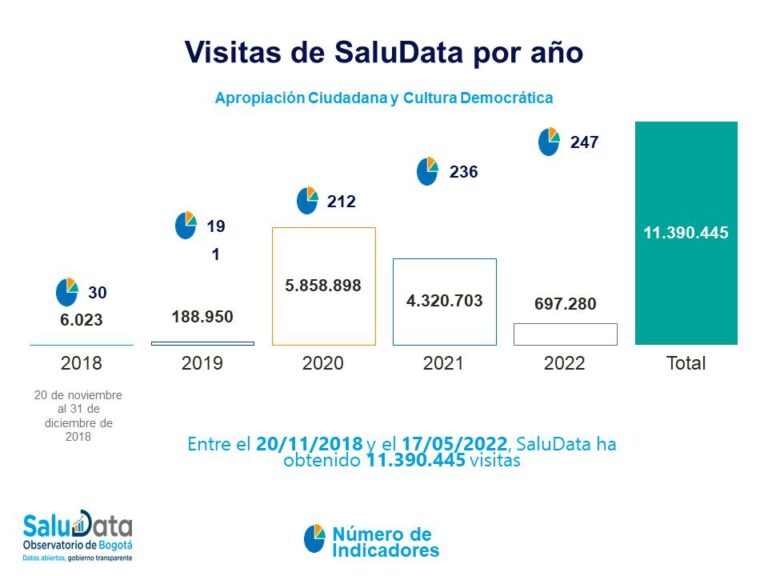
Con un sistema de información implementado al inicio de la pandemia por COVID-19, el Observatorio de Salud de Bogotá (SaluData) ha informado durante más de 750 días consecutivos el estado epidemiológico de la ciudad, con el cruce diario de 52 bases de datos integradas y automatizadas usando herramientas analíticas y de Big Data.
La coyuntura por la emergencia sanitaria causada por la COVID-19 se convirtió en un reto y una oportunidad de innovación para el Observatorio de Salud de Bogotá, pues era necesario que tomadores de decisiones y ciudadanos contaran con la misma información.
SaluData inicia su operación en noviembre de 2018 con 30 indicadores y 6.023 visitas. En 2020, con 212 indicadores, uno de estos las 21 páginas de COVID-19, alcanzan 5.858.898 visitas. Actualmente, con el uso de herramientas de Big Data, llegó a más de diez tableros implementados con estos desarrollos.
Natalia Rodríguez Moreno, coordinadora del Observatorio, señala que antes de la pandemia el sector salud intentó implementar herramientas de Big Data, pero solo la llegada de la pandemia obligó a su utilización. “Iniciamos en pandemia con bases de datos aisladas, con información que no dialogaba entre sí. Pero la pandemia y la necesidad de mantener informado al ciudadano diariamente nos obligó a implementar herramientas que otros sectores ya usaban hace muchos años. Alrededor de mayo-junio de 2020 montamos un sistema de información para COVID-19; empezamos, con nueve bases de datos y, al finalizar la pandemia, teníamos 52 bases de datos interoperando diariamente, porque no había ninguna otra forma de mantener al ciudadano informado diariamente”.
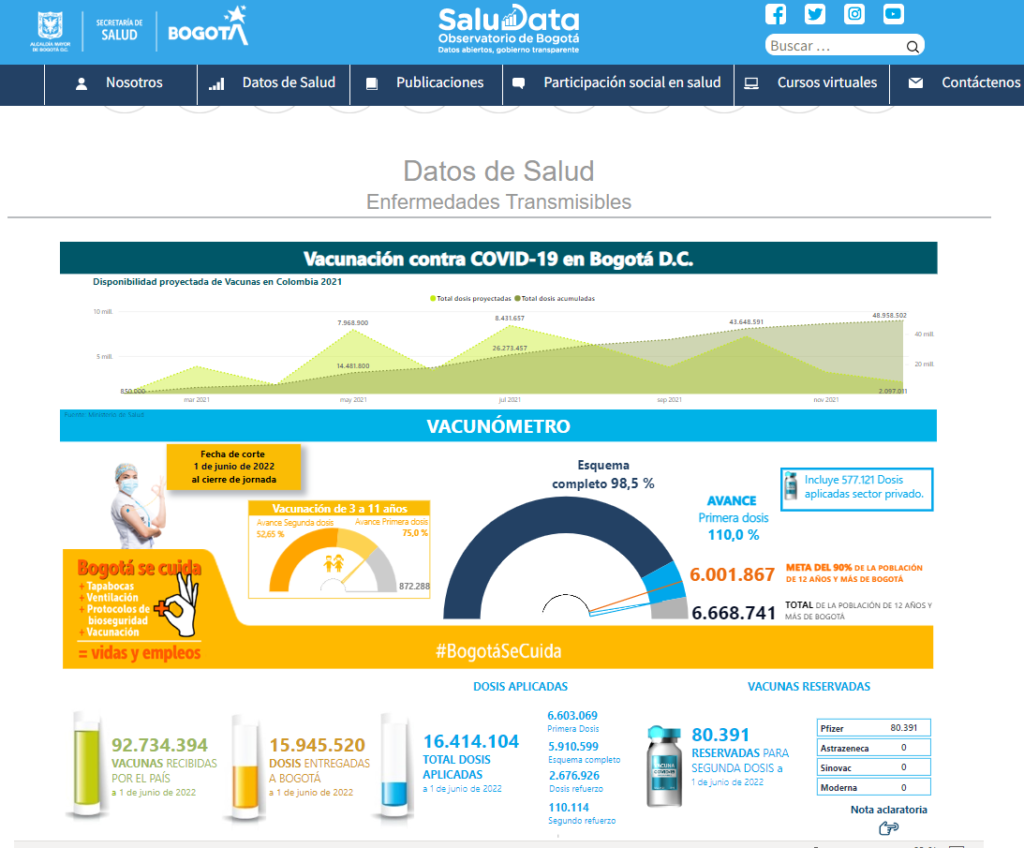
Las 21 páginas con información de COVID se condensaron en 15 páginas, incluyendo todo lo relacionado con casos confirmados y recuperados, pruebas, unidades de cuidado intensivo (UCI), camas de hospitalización, RT, mapas de calor por casos y por localidad; este fue el primer paquete de indicadores. Un segundo paquete fue el de vacunación COVID, con el Vacunómetro, que informa diariamente sobre el avance del proceso por número de vacunas recibidas y aplicadas, reservas, grupos etarios, avances en primeras y segundas dosis y en dosis de refuerzo, esquemas completos, etc.; Bogotá fue el primer ente territorial en poner la información de vacunación COVID a disposición de la ciudadanía. El tercer paquete contó con información exclusivamente de UCI, tanto de atención general como para COVID.
El Sistema Unificado de Información de SaluData, usando herramientas analíticas y de Big Data, traducidas en siete tableros de información, con desagregación de datos a nivel poblacional, territorial, atención, pruebas diagnósticas, búsquedas activas de casos, vacunación, entre otros, ha permitido lo siguiente:
- Dar a conocer la situación epidemiológica de la ciudad mediante una comunicación efectiva del riesgo.
- Disponer de datos útiles para la simulación de diferentes escenarios epidemiológicos que orienten la preparación del sistema de salud para cada uno de estos, y garantice así la capacidad de respuesta hospitalaria.
- Contar con datos que favorezcan diferentes tipos de análisis de la información.
- Generar alertas tempranas que permitan tomar decisiones focalizadas, como fue la restricción en la movilidad en las localidades de Bogotá, la restricción en el ingreso a establecimientos abiertos al público, entre otras medidas.
- Facilitar el ejercicio de rectoría en salud, monitoreando el desempeño de los actores del sistema en el marco de la Pandemia, como EAPB, laboratorios, IPS, entre otros.
- Favorecer el seguimiento al acceso de los servicios de salud en la Pandemia como oportunidad en diagnóstico, toma de pruebas, cobertura de vacunación en los diferentes grupos poblacionales, entre otros.
“SaluData es una herramienta de la Secretaría de Salud, un trabajo de todas sus áreas. No contratamos a un externo para producir, operar o construir SaluData; esto fue una producción in-house (in-house production), de manera que con la Dirección TIC, Comunicaciones, Salud Pública, Aseguramiento, Planeación, cada área puso un granito de arena para que esté operando. Hay un equipo dedicado exclusivamente a operar SaluData, pero requiere recibir la información y la asesoría técnica de todas las áreas”.
Externamente se contó con el acompañamiento de las Entidades Administradoras de Planes de Beneficio (EAPB), que entregaron la información necesaria para optimizar la toma de decisiones durante la pandemia. Otra entidad externa fue la Cuenta de Alto Costo, entidad rigurosa con todos sus protocolos de manejo de información. Se trabajó con el Ministerio de Salud y el Instituto Nacional de Salud, mediante conexiones a sus sistemas de información. Pero también se trabajó con las Instituciones Prestadoras de Salud (IPS) e importantes actores privados del sistema de salud, como la academia, periodistas y medios de comunicación, entes de control, entre otros.
Señala Rodríguez Moreno lo siguiente: “La apuesta es implementar paso a paso, de nuestros 246 indicadores ya tenemos 7 automatizados. La idea es que paulatinamente todos migren a implementarse con herramientas de Big Data. También hay un proyecto grande de analítica con varios casos de uso, para responderle a las directivas ciertos cuestionamientos respecto de problemas de salud en la ciudad: se están usando herramientas de Big Data pero todos los proyectos a corto, mediano y a largo plazo que están en el radar de la Secretaría de Salud”.
La coordinadora del Observatorio señaló que un gran reto es la pedagogía del dato: “Es un gran reto seguir trabajando con el ciudadano informado, ciudadanos de a pie, académicos, periodistas, tomadores de decisiones. La pedagogía del dato debe ser una práctica implementada en el sector público en general, porque es el de más alta desconfianza entre los ciudadanos; entonces, ganar esa confianza con el ciudadano, que en parte la ganamos de manera importante, ha sido un aprendizaje y una ganancia de confianza, ha dado frutos”.
Una ganancia importante fue lograr el canal de doble vía con el ciudadano, porque escriben y retroalimentan al Observatorio. Por ejemplo, en un indicador diferente a COVID, como lo es el intento de suicidio, toda la información está desagregada por localidad, distrito, con series temporales importantes, edad, sexo, el análisis, la descarga de datos y la ficha técnica con que se construyó el indicador. Indica Rodríguez Moreno lo siguiente: “Hemos recibido más de 5.000 comentarios que nos han ayudado a mejorar la página web para que sea entendida por todos y a optimizar la forma de comunicarnos con el ciudadano. Es otra de las grandes experiencias, como también los talleres realizados con periodistas, ciudadanos, la academia, y un valioso trabajo articulado entre el sector público y privado”.
Rodríguez Moreno concluye: “Debe promoverse más el diálogo, que el Gobierno abrió entre sectores, tanto intrasector como intersector. También, [es preciso] ser muy conscientes durante la formación del talento humano en salud, que ese dato que registran en la historia clínica, en la atención al paciente, en el RIPS (Registro Individual de Prestación de Servicios), en el Sivigila; luego, se traduce en inversión en política pública. Si desde la formación no hay conciencia de registrar bien una ficha de Sivigila, si no pone el código correcto, esto invisibiliza problemas en salud y se traduce en una inversión pública basada en datos erróneos. Si los datos no se diligencian con enfoque poblacional y de género, por limitaciones de tiempo y problemas del sistema de salud, la toma de decisiones basada en estos datos termina siendo absolutamente reducida en términos de enfoque de género, de etnias, se invisibiliza la situación de esta población por esta falencia en los datos”.
Asimismo, agregó que también es fundamental e indispensable la integración con los otros sectores, con las demás Secretarías de Gobierno, así como mantener ese diálogo permanente con los otros sectores. Además, es necesario participar en redes de conocimiento, escuchar a la academia permanentemente, porque esa retroalimentación favorece las mejoras.
Hoja de ruta para un ecosistema digital e inteligente en salud en Medellín
En una iniciativa interinstitucional en el contexto Medellín Valle del Software, con la cual se busca articular un ecosistema enfocado en acelerar y potenciar la implementación de las industrias 4.0 en la región (EcoMDE4.0), en 2021 se formuló el modelo de industria 4.0 que posicione a Medellín como Ecosistema digital e inteligente, a través de la interacción de actores clave, el diseño de la hoja de ruta estratégica y la estructuración de macroproyectos, con el fin de potenciar el empleo, las capacidades laborales de alto valor agregado y la competitividad empresarial de las industrias claves de la región, en el marco de la estrategia de Especialización Productiva.
Con base en la información aportada por los actores, se construye un mapa de Ecosistema de Salud Mediada por Tecnología, en el cual se identifican acciones que desarrollar por seis tipos de actores y en tres horizontes de tiempo.
Un elemento clave que es preciso considerar es la creación de centros de innovación en salud y tecnología donde participen todos los actores, así como en la generación de un sistema de gestión de la información en salud que se convierta en un símil de la mátrix de la salud en la cual todos los actores se puedan apoyar.
En el proyecto tipo de Ecosistema se decide intervenir un problema de salud desde los componentes básicos de la Salud Mediada por Tecnología: Big Data, Data Mining, Interoperabilidad, Plataformas digitales, Equipos biomédicos.
Uno de los objetivos de la incorporación de la 4RI al sector salud es mejorar la eficiencia y contribuir al bienestar de la población, pero algunas de estas tecnologías llegan a presionar las finanzas de los sistemas de salud por sus altos costos, y muchos hospitales y centros médicos no podrán financiar proyectos tan grandes para hacer una transformación digital profunda y completa. Por lo tanto, se requerirán esfuerzos regulatorios, éticos y fiscales que determinen las formas de relacionamiento entre los actores, las formas de pago y los procesos orientados a optimizar el uso de los recursos.
Alianza Caoba
En Medellín se constituyó la Alianza Caoba, un centro de excelencia y apropiación que apoya el uso de las tecnologías de Big Data y Data Analytics, a través de diferentes frentes que incluyen la formación del talento humano, la investigación aplicada y el desarrollo de productos a la medida.
Esta alianza público-privada surgió en 2016 para generar soluciones innovadoras en diversos sectores industriales, gubernamentales y académicos, aprovechando la capacidad investigativa de las universidades y el uso de las tecnologías de Big Data y Data Analytics. Además, está integrada por las empresas Grupo Bancolombia, Grupo Nutresa, IBM de Colombia, SAS Institute Colombia, DELL, Cluster CREATIC y las Universidades ICESI, EAFIT, Los Andes y la Pontificia Universidad Javeriana, que actúa como ejecutor del proyecto.
Entre los proyectos destacados que ha ejecutado la Alianza Caoba, están en desarrollo y evaluación de modelos matemáticos y epidemiológicos que apoyen la toma de decisiones en atención a la emergencia por SARS-Cov-2 y otros agentes causales de IRA en Colombia utilizando Data Analytics y Machine Learning”. Pero también está la analítica de datos para estimar el riesgo de desnutrición de niños y niñas en Colombia, en el marco de la emergencia por COVID-19.
En materia de salud, señalan que combinar toda la información obtenida del Big Data en salud para aprender y poder tomar decisiones orientadas hacia el usuario es el principal reto al que se enfrenta el sector salud.
Qué está pasando con la formación del talento humano de cara a la transformación digital
“En la transformación digital, el manejo de la información es un componente transversal y relevante a la luz de lo que se quiera hacer. No es solamente la tecnología, porque el manejo del dato, reconocer el dato y hacer un manejo adecuado de ese dato, es parte de la columna vertebral del proceso de transformación digital”.
Con estas palabras, Mauricio Alexander Alzate, coordinador de la Maestría en Tecnologías de la Información y Comunicación en Salud en la Universidad CES, recalca la importancia del talento humano en los procesos de transformación digital en organizaciones públicas y privadas.
Agregó que es fundamental que las personas involucradas en estos procesos sean capaces de entender cuáles son los datos relevantes en su institución, así como qué información de esos datos puede ser de valor para esa institución y ser capaz de generar tableros de control y de analítica para gestionar esa información. Por eso, y ante la necesidad de formar el talento humano que es clave para hacer ese manejo de los datos en los procesos de transformación digital, varias universidades del país desarrollaron una oferta académica en la materia.
La Universidad CES, por ejemplo, reconociendo que el manejo de datos es relevante y vital para la toma de decisiones en salud, ofrece la Maestría en TIC en Salud y desde este año el Diplomado virtual Big Data en Salud, que presenta los conceptos básicos de Big Data para el sector salud y las posibilidades de aprovechar su potencial para beneficio de la gestión hospitalaria. Además, explora oportunidades de valor e introduce estrategias metodológicas para brindar competencias básicas en uso de datos y su transformación en información, y así aportar a la toma de decisiones.
El plan de estudios incluye el contexto de los datos en el sector salud, modelos y técnicas de analítica de datos para la toma de decisiones, análisis estructural sectorial, tableros de control y software especializado, así como el papel de la analítica de datos y Big Data en la salud.
Por su parte, la Universidad de Los Andes ofrece la Maestría en Inteligencia Analítica para la Toma de Decisiones – (Analytics), que busca formar profesionales entrenados en el uso eficiente de datos, mediante la aplicación de técnicas descriptivas, predictivas y prescriptivas para soportar el proceso de toma de decisiones, la creación de ventajas competitivas y la generación de valor en las organizaciones.
La Universidad Javeriana tiene un Diplomado online en Analítica de Datos, cuyo propósito es promover una actitud analítica basada en datos para resolver problemas organizacionales, generando modelos descriptivos y predictivos que le permitan a las empresas fortalecer sus ventajas competitivas.
La especialización en Big Data de la Uniminuto – Centro regional de Madrid (Cundinamarca) ofrece conocimientos específicos en nuevas tecnologías aplicables a la información y su debido tratamiento. La Universidad Compensar también tiene una Especialización en Big Data para formar expertos en analítica de grandes volúmenes de datos, que generen valor a las organizaciones a nivel de Business Intelligence.
La Universidad Jorge Tadeo Lozano tiene un Diplomado en Big Data y Analítica para Comunicadores, cuyo objetivo es formar periodistas de datos en un campo ubicado en la intersección de habilidades o capacidades tecnológicas, analíticas, narrativas y éticas, que integra conocimientos de diversas disciplinas como data mining y machine learning, analítica de datos y visualización de la información, sociología computacional y simulación social, ética digital, periodismo de datos y storytelling.
La Universidad El Bosque ofrece un Diplomado virtual en Big Data, enfatizando que, ante la ingente cantidad de datos que se producen desde diferentes fuentes, es imperativo contar con estrategias y herramientas como analítica y Big Data que permitan la acertada toma de decisiones, haciendo uso de la estadística y el análisis computacional. La Universidad EIA ofrece la Especialización en Big Data e Inteligencia de Negocios, un programa para abordar la problemática de transformación de los datos en información que permita agilizar la toma de decisiones.
La Universidad Nacional de Colombia – Sede Bogotá ofrece el programa de formación virtual Machine Learning and Data Science MLDS. La ciencia de datos (o data science, en inglés) aborda el análisis y explotación del creciente volumen de datos. Se trata de una nueva área del conocimiento donde confluyen herramientas técnicas y conceptuales como la estadística, el aprendizaje computacional, el manejo de grandes volúmenes de datos (Big Data) y la visualización de información. Por su parte, la Universidad Nacional de Colombia – Sede Medellín tiene el Grupo de Investigación Big Data y Data Analytics.
Uniandes creó visualizador del fenómeno COVID-19 en Colombia
Un equipo interdisciplinario de la Universidad de Los Andes creó en 2020 una herramienta de visualización de datos con información sobre el avance de la Pandemia en Colombia, a partir de datos generados por el Instituto Nacional de la Salud (INS), la Secretaría de Salud de la Alcaldía de Bogotá y el Laboratorio de Secuenciación Gencore para el análisis de COVID-19 de la Universidad.
El sitio web fue creado con mapas y gráficos interactivos para visualizar de forma clara y ordenada las estadísticas de casos de COVID-19 en Colombia. Por ejemplo, la herramienta permite desglosar la información por sexo y edad, así como el tipo de caso, lugar de atención, país de precedencia, lugar de residencia y estado clínico, características muy útiles para revelar la desigualdad en la distribución de casos, muertes y asignación de recursos en función de la edad y género, entre otras variables sociodemográficas fundamentales para hacer frente a la Pandemia.
Desarrollos de Big Data en la prestación de servicios de salud, caso Hospital Pablo Tobón Uribe

Aunque en el Hospital Pablo Tobón Uribe de Medellín aún no se ha incursionado en proyectos que incluyan variedad de datos como audios o imágenes, desde 2019 se han desarrollado algunos proyectos que procesan gran volumen de datos y generan valor al hospital, como:
- Aplicación para la búsqueda de pacientes que cumplan criterios de protocolos de investigación, de acuerdo con ciertas características como diagnósticos, procedimientos, medicamentos, laboratorios y datos clínicos.
- Desarrollo de modelos de datos con énfasis en estadística descriptiva, el cual contiene dashboards (tablero o cuadro de mandos) interactivos de procesos asistenciales y/o administrativos
- Participación con la Universidad EIA en un protocolo de investigación, cuyo objetivo es: “Desarrollar un modelo predictivo que mejore la toma de decisiones clínicas en las Unidades de Cuidado Intensivo (UCI) Adultos del Hospital Pablo Tobón Uribe, con base en el análisis de datos históricos proveniente de múltiples fuentes utilizando técnicas de Big data e inteligencia artificial”.
- Participación en el proyecto de investigación observacional retrospectivo para caracterizar la enfermedad y la vía de tratamiento en el cáncer de próstata, basado en información de registros médicos electrónicos y utilizando procesamiento del lenguaje natural e inteligencia artificial con Janssen Research & Development.
En el desarrollo de estos proyectos han participado dependencias internas como el Departamento de Informática en Salud, Departamento de Tecnologías de la Información y Comité de Dirección. Asimismo, con el acompañamiento de entidades externas como la Universidad EIA, Janssen Research & Development (SAVANA) y MANAR.
El Hospital ha invertido en estos desarrollos de Big Data alrededor de $380.000.000. Cada proyecto tiene su propio presupuesto y las licencias de las aplicaciones se renuevan cada año.
Implementar el Big Data en el Hospital Pablo Tobón Uribe ha constituido una experiencia satisfactoria que ha arrojado buenos resultados para la entidad. Como lecciones aprendidas se pueden mencionar la inclusión del líder que toma las decisiones con base en los datos desde la detección de la necesidad, de manera que no sea algo forzado por el equipo tecnológico; adicionalmente, contar con profesionales formados en temas de Big Data y similares.
Un logro importante es poder iniciar en la institución una transformación digital basada en los datos y contar con información que apoya la toma de decisiones, así como optimizar procesos operativos en roles de análisis y gestión de procesos, además de la detección de los pacientes para protocolos de investigación de manera más oportuna.
Entre los proyectos en Big Data que considera el Hospital para el mediano y el largo plazo, se contempla el uso de técnicas de Procesamiento de Lenguaje Natural que permita extraer información de datos no estructurados, para los reportes de la Cuenta de Alto Costo y/u obligatorio cumplimiento y desarrollar proyectos relacionados con Machine Learning y Deep Learning (modelos predictivos).
Desarrollos de Big Data en el aseguramiento en salud, la experiencia de EPS Sura

Una de las compañías de aseguramiento en salud que ha implementado en su gestión desarrollos de analítica e Inteligencia Artificial es EPS Sura, con algunas iniciativas, inmersas en el paradigma de Big Data, así:
- Complicaciones COVID. Es un modelo de clasificación que mide la probabilidad condicional de que una persona que tenga COVID-19 ingrese a una Unidad de Cuidados Intensivos (UCI) o fallezca. Lo hace a partir de la identificación de variables de comorbilidad, ayudas diagnósticas, sociodemográficas, hábitos y consumo de servicios. Este modelo fue empleado para priorizar la atención y la oferta de servicios a posibles contagiados durante la Pandemia, obteniendo buenos resultados de costo-efectividad y gestión de riesgos de poblaciones en su implementación, así como apalancando la reducción de la letalidad en un 30% respecto al país.
- Pretamizaje COVID. En un artículo de 2020, investigadores del MIT (Instituto Tecnológico de Massachusetts, EU) construyeron un modelo de redes neuronales (aprendizaje profundo), en el que fueron capaces de reconocer con buena precisión la presencia de COVID-19 a partir de registros de voz y tos de pacientes (1). Al interior de SURA se replicó dicho paper, usando datos internos. Se desarrolló un aplicativo web, que estuvo disponible en algunas IPS de la Compañía para capturar los audios de las personas que iban a realizarse una prueba PCR por sospecha de contagio del virus. De esta forma se pudo recolectar suficiente cantidad de datos para mejorar el entrenamiento del modelo y ponerlo a disposición de los canales de entrada, para hacer la priorización de las ayudas diagnósticas y la atención a estas personas.
- Índice de desenlaces. El riesgo en salud es la probabilidad de ocurrencia de un diagnóstico no deseado, evitable y negativo. Desde esta definición se desarrolló una iniciativa para generar gestión del riesgo de forma exante, y no solo antelar la ocurrencia del evento, sino poder modificar su presencia a través de la gestión de variables vulnerables ante la intervención. Esta metodología consta de una serie de modelos predictivos de desenlaces crónicos, que miden la probabilidad de ocurrencia de estos en un rango de tiempo. Actualmente, dicha herramienta es una de las estrategias de la EPS para generar gestión de personas saludables e incorpora los siguientes diagnósticos: enfermedad renal crónica (ERC), hipertensión arterial (HTA), diabetes mellitus tipo II (DM), infarto agudo de miocardio (IAM), eventos cerebrovasculares isquémicos (ECVI), insuficiencia coronaria y anginas (EAC).
- Probabilidad de cancelación y permanencia en Planes Complementarios. El objetivo del análisis fue facilitar la gestión de las cancelaciones y permanencias del Plan Complementario, a través de metodologías que permitieron conocer la probabilidad de cancelación y permanencia de los afiliados, de acuerdo con los tipos de plan, variables sociodemográficas, comportamiento de uso del servicio e intermitencias previas. Se implementó un modelo analítico basado en redes neuronales convolucionales. En ambos casos (análisis de cancelaciones y permanencias PAC), la información brindó herramientas y métodos de priorización con el fin de implementar estrategias de fidelización que permitieran retener a aquellos afiliados con buena siniestralidad, pero con alta probabilidad de cancelar y seguirles ofreciendo un servicio diferencial. Con esto se logró la reducción de la tasa de cancelación en un 30%.
Hacen parte del plan de trabajo los siguientes temas: gestión de ineficiencias, crecimiento rentable del ingreso, analítica de PQR y tutelas, optimización de la oportunidad en programación de servicios y predicción de rehospitalización.
Para esta compañía de aseguramiento en salud, los principales retos están en la calidad de los datos, lo cual determina el propósito de construcción de los transaccionales, así como la necesidad de captar variables del comportamiento humano más enriquecidas, como hábitos, bienestar emocional, etc. Adicionalmente, se debe seguir trabajando por descentralizar la información e implementación de herramientas tecnológicas robustas.
“El ADN de la Cuenta de Alto Costo es el manejo de la Data”
“El ADN de la Cuenta de Alto Costo es el manejo de la Data, de un gran volumen de datos, porque nuestra misión es estructurar e implementar un sistema de información que permita a los actores del sistema de salud saber dónde están los pacientes con enfermedades de alto costo, cómo son atendidos en el sistema, conocer la gestión de estos pacientes, qué oportunidad tienen, con qué frecuencia les hacen un procedimiento, cuál es su terapia. Eso nos permite como sistema de salud, conocer si hay o no un acceso efectivo al proceso de atención de estos pacientes”.
Con estas palabras describió Lizbeth Acuña Merchán, directora de la Cuenta de Alto Costo (CAC), la utilización de Big Data como razón de ser de la entidad. Y explicó: “Desde que nació la Cuenta hace 15 años, tenemos un conjunto de datos robusto que nos permite trabajar para generar información. El Big Data nació hace más de 30 años, pero ahora es el boom al cobrar importancia para la toma de decisiones a partir de los datos. Desde que se creó la Cuenta, tenemos una bodega de datos en dónde se procesan, se analizan y se genera información para el sector salud”.
Por ello desde los inicios de la CAC se crearon estandarizaciones de las estructuras de las bases de datos, para garantizar su calidad, aclaró la directiva: “Esto no solamente viene desde la captura del dato, sino desde su gestión, su procesamiento, y es ahí donde incorporamos tecnologías que nos permiten hacer validaciones, algoritmos, etcétera, para generar herramientas que nos permitan tener más allá de un dato, de una analítica descriptiva, pasar a una analítica predictiva. Ahí incorporamos herramientas de Inteligencia Artificial para trascender esa información y ese gran volumen de datos que hoy en día tenemos en la Cuenta de Alto Costo”.
A partir del Big Data, en la CAC iniciaron modelos estadísticos descriptivos y luego incorporaron herramientas para describir las enfermedades de alto costo y su comportamiento, más allá de la estadística y la matemática. Explica Acuña Merchán: “Esto para incursionar en el Business Intelligence, que todavía es análisis descriptivo, y dar un salto a modelos importantes donde combinamos datos estructurados y no estructurados con gran éxito, aplicando el procesamiento del lenguaje natural que hoy nos permite desarrollar un 40 % del proceso de auditoría de estos datos, para garantizar no solo su calidad sino también que para través de esos algoritmos podamos identificar las ineficiencias en los procesos de atención a los pacientes de alto costo”.
Las herramientas, modelos y desarrollos de Big Data en la CAC son producción in-house, a partir de la experiencia de médicos, enfermeras, matemáticos, estadísticos, epidemiólogos, economistas, profesionales de salud, científicos de datos, e ingenieros industriales y de sistemas, que sumaron conocimientos.
Señala la directora de la CAC: “Esa capacidad técnica propia nos permitió construir las herramientas que hoy disponemos gratuitamente para uso del sector salud. Los desarrollos que hemos creado son de la Cuenta de Alto Costo, desde el personal de la Cuenta hemos co-creado con todos los actores herramientas que se necesitan en el sector. Por ejemplo: construimos el análisis predictivo para COVID-19 durante la pandemia de 2020, un modelo predictivo en cáncer de mama y otro tipo de herramientas. A partir de las necesidades identificadas de los actores del sistema, co-creamos con las EPS, con los prestadores, con los pacientes, con la academia, con las sociedades científicas, y con base en las necesidades de esos actores establecemos unos grupos de trabajo. Ahí es donde hacemos un aporte importante para desarrollar este tipo de herramientas”.
Falta cultura organizacional y usabilidad para aprovechar el Big Data en salud
La directora de la Cuenta de Alto Costo señaló que una de las más importantes lecciones aprendidas en la implementación de Big Data, es reconocerlo como una estructura técnica compleja, que es muy útil para la toma de decisiones. Sin embargo, ahí una gran dificultad, indica Acuña Merchán: “Hemos identificado que no hay cultura organizacional y estratégica para convertir los datos en decisiones y esas decisiones en acciones. Se pueden generar muchas herramientas, la información está disponible para la toma de decisiones, pero si la usabilidad es muy baja es un problema importante porque las empresas del sector salud no reconocen la relevancia de estas tecnologías, ni que el Big Data reduce costos, que es mucho más rápido y mejor para la toma decisiones, ni que a partir de ahí se generan nuevos productos y servicios para las entidades y para beneficio del paciente”.
Señaló, por ejemplo, que desarrollan una herramienta o un modelo predictivo, lo dejan disponible para el uso por actores del sector salud, siendo de gran utilidad para planear y asignar recursos, para ver el deterioro de los pacientes si no se hacen intervenciones, “y nos hemos llevado la sorpresa de que, aun estando disponibles, las entidades no los usan, o los conocen, pero no los usan, y cuando no se usan es una frustración muy grande, porque es como si no existieran”.
La directora de la CAC concluyó que existen dos grandes retos en el tema: “Para el manejo del Big Data en el país está pendiente el compromiso ético y responsable en el manejo de los datos por parte de todos los actores. Hay un componente esencial: el hecho no es tener la información, lo más importante es qué hacer y cómo trabajar con ese gran volumen de datos, teniendo en cuenta que parte de un principio ético de protección al usuario, de protección a la información”.
Y el segundo reto es la capacitación en la materia: “El Big Data no es solamente uso de tecnología, es necesario hacer un entrenamiento importante de todos los actores que participan en el sistema de salud, tanto profesionales de la salud como de otras áreas, porque si no hay ese conocimiento no podremos avanzar tan rápido como queremos hacia esos ecosistemas digitales que necesitamos construir a partir de este volumen de datos”.